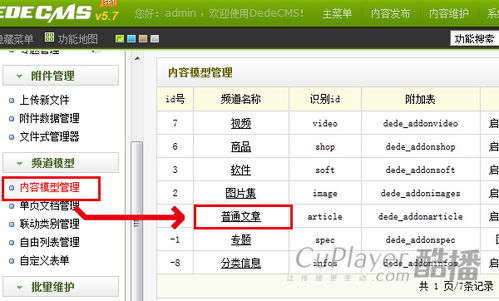
解決科訊CMS系統采集信息時“在截取列表時出錯”問題

當您在科訊(Kesion)CMS系統中使用信息采集功能,并遇到“在截取列表時出錯”的提示時,這通常意味著系統在嘗試根據您設定的“列表開始標簽”和“列表結束標簽”來識別和抓取目標網頁上的文章列表時失敗了。這個問題會中斷采集流程,導致無法進入下一步設置。下面將詳細分析原因并提供系統的解決步驟。
問題原因分析
此錯誤提示的核心在于CMS的采集器無法在您提供的網頁源代碼中,準確定位到您所設定的列表區域。具體原因可能包括:
- 標簽不準確:您輸入的“開始標簽”和“結束標簽”可能不是唯一的,或者在目標頁面的源代碼中不存在、已發生變化。
- 動態加載內容:目標網站的列表可能是通過JavaScript動態加載的(Ajax技術)。科訊CMS的采集器默認抓取的是靜態HTML源代碼,無法獲取動態生成的內容。
- 網頁編碼問題:源網頁的編碼(如UTF-8, GB2312)與采集器解析時使用的編碼不一致,可能導致標簽字符識別錯誤。
- 規則沖突:可能與其他采集規則(如分頁規則)產生了沖突,導致系統解析混亂。
詳細解決步驟
請按照以下流程逐一排查和嘗試:
第一步:重新檢查并確定列表標簽
這是最基礎的步驟。
- 在瀏覽器中打開您要采集的目標列表頁。
- 在頁面空白處右鍵單擊,選擇“查看網頁源代碼”或按
Ctrl+U。 - 在源代碼頁面,按
Ctrl+F搜索您認為的列表項特征代碼(例如,每個文章標題都包裹在` 標簽內,或者有共同的class如class="news-item"`)。 - 關鍵點:找到包裹 整個列表區域 的起始代碼和結束代碼。例如:
- 開始標簽:可能是
<div id="news-list">或<ul class="article-list">。
- 結束標簽:對應地是
</div>或</ul>。
- 確保您復制的標簽是完整且準確的,包括尖括號和屬性。
第二步:處理動態加載內容
如果列表是滾動加載或點擊“加載更多”才出現的,說明是動態內容。
- 嘗試直接抓取分頁URL:尋找網站是否有傳統的、帶有頁碼(如
page=2)的列表分頁鏈接,直接采集這些靜態分頁。 - 使用高級采集工具或插件:科訊CMS自帶的采集器可能功能有限。對于復雜的動態網站,可能需要借助更專業的第三方采集軟件(如火車采集器、八爪魚等),先將數據采集下來,再通過科訊CMS的后臺數據導入功能進行添加。
第三步:調整采集設置
在科訊CMS采集設置中,進行以下嘗試:
- 編碼設置:在采集規則的“基本設置”或“高級設置”中,嘗試手動修改“網頁編碼”為源網頁的編碼格式(通常源代碼第一行會有
charset=gb2312或charset=utf-8的提示)。 - 簡化規則:暫時清空或取消“內容分頁”、“過濾規則”等高級設置,只保留最核心的列表標簽規則,測試是否能通過列表識別這一步。
- 使用通配符:如果列表項的HTML結構有微小的變化(例如ID號不同),可以在標簽中使用通配符
<em>。例如,開始標簽可以寫成<div class="list</em>" id="list_*>,以匹配更廣泛的情況。
第四步:其他通用排查
- 更新CMS和采集組件:確保您使用的科訊CMS版本及采集功能組件是最新的,舊版本可能存在兼容性問題。
- 檢查網絡與權限:確保服務器可以正常訪問目標網站,且沒有被對方防火墻或Robots協議屏蔽。
- 查看系統日志:登錄科訊CMS后臺,查看系統錯誤日志或采集日志,有時會提供更具體的錯誤信息。
針對“淄博CMS”用戶的特別提醒
如果您是淄博地區的用戶,除了上述通用方法,還需注意:
- 本地化服務:可以聯系為您提供技術支持的本地網絡公司或科訊CMS的授權服務商。他們可能對當地常用網站的結構更熟悉,能快速提供標簽規則。
- 案例參考:如果您采集的是淄博本地網站(如淄博新聞網、政務網站等),可以嘗試在網上搜索是否有其他科訊CMS用戶分享過針對該站點的成功采集規則。
###
“在截取列表時出錯”本質上是一個規則匹配問題。解決它需要您像一個偵探一樣,仔細分析目標網頁的HTML結構。從 “精確復制標簽” 入手,排除動態內容干擾,再輔以編碼、規則等設置的微調,通常能夠解決大部分問題。對于極其復雜的網站,考慮使用專業采集工具作為補充方案是更高效的選擇。
如若轉載,請注明出處:http://www.w38.com.cn/product/591.html
更新時間:2025-12-25 20:06:29